Pratique : Markdown et extraction de données pour FileMaker 14
Il y a un domaine dans lesquel Markdown peut astucieusement se glisser tout en préservant le poids des fichiers, c’est celui des bases de données.
L’objet de ce pratique sous OSX est de se souvenir que l’on peut s’épargner bien des soucis de mise en forme lors de l’extraction de champs concatènés en les saupoudrant astucieusement de balises Markdown. Et obtenir un fichier .txt qui pourra ensuite être employé tel quel et directement dans un traitement de texte Markdown. Ou basculé en RTF ou en .docx depuis ce dernier outil ou un autre. Bref, comme l’énonce la formule attribuée à Lavoisier, “Rien ne se perd, rien ne se crée, tout se transforme” (et c’est assez bien l’esprit du Markdown…).
En amont, nous sommes partis de FileMaker Pro qui est proposé désormais en version 14 sous OSX.
À l’origine FileMaker appartenait à Forethought, Inc. (tout comme PowerPoint pour mémoire…!) avant de devenir la propriété d’Apple. Ce produit ne cesse d’ajouter de nouvelles options au fil des ans (avec, certes, quelques ruptures dans la compatibilité des fichiers). Mais le réduire à un simple outil de base de données est fort réducteur. FileMaker est une jeep, un outil que vous pouvez bricoler, modeler aisément pour des besoins ponctuels sans pour autant partir dans la création de bases relationnelles lourdes…!
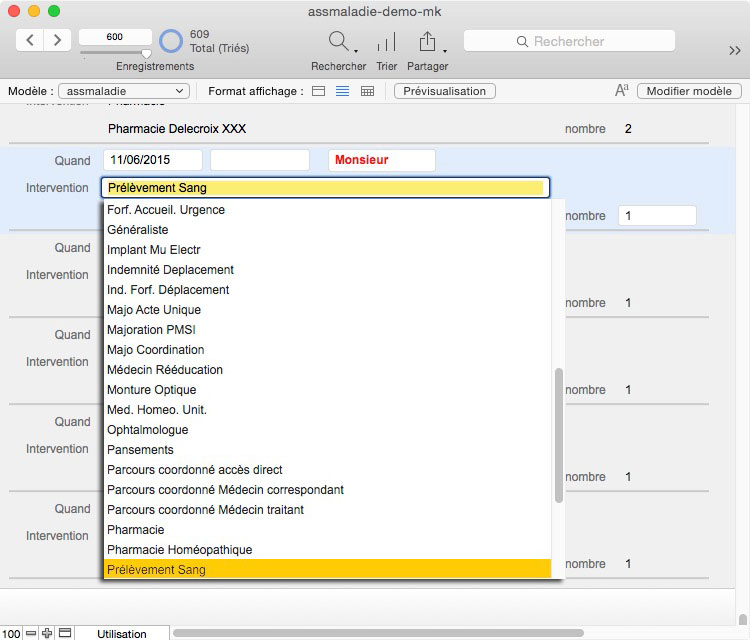
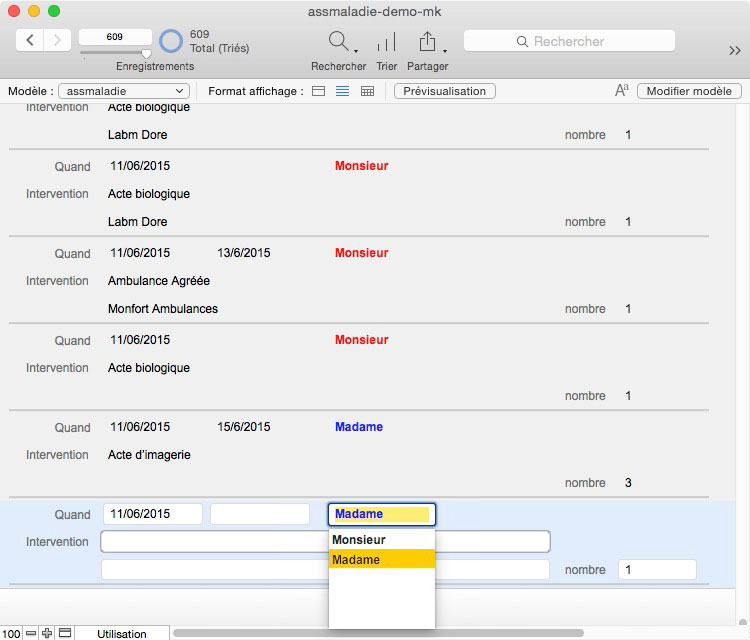
Notre exemple est tiré d’une saisie d’informations depuis des feuillets de l’assurance maladie pour reconstruire une chronologie. Comme les remboursements ne s’effectuent pas en même temps, il n’est pas rare de trouver des actes résultant d’une même prise en charge hospitalière dans plusieurs envois successifs et le désordre le plus total. La seule manière de débrouiller l’écheveau est d’entrer brutalement toutes les données (simples rappels ou notifications de paiements) puis de trier sur date pour afficher les opérations. Et enfin, ne conserver que celles qui évoquent le règlement aux intervenants de santé. Comme ce sont de vraies données, tout a été remis à la date de l’article juste par souci de confidentialité et largement édulcoré…
Mais, pourquoi faire cela dans un tel outil alors qu’un traitement de texte suffirait…? En premier lieu, pour la gestion des rubriques répétitives. Ce à l’unique condition de bien les saisir la première et unique fois. Puis pour la souplesse de mise en forme de l’ordre de lecture en second lieu.
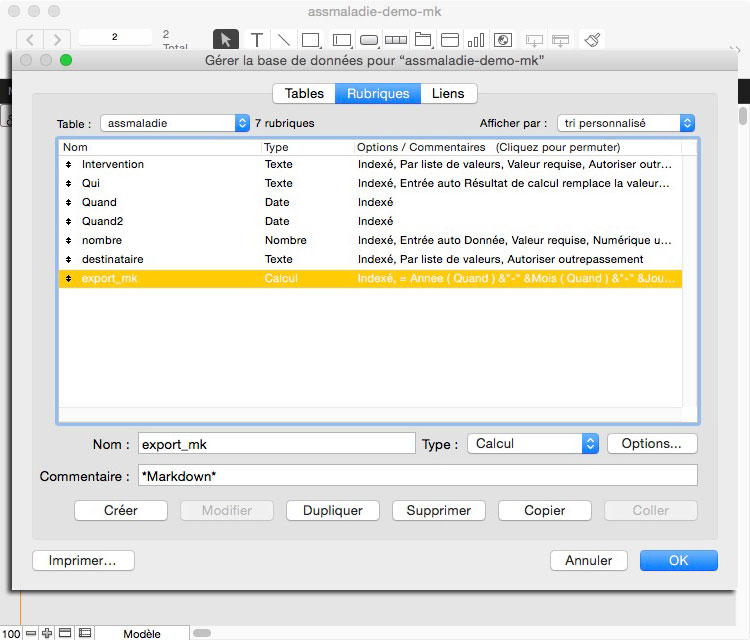
En amont, lors de la saisie des informations, le mode le plus dépouillé est à conserver, juste anticiper le découpage des rubriques pour des traitements ultérieurs. Se souvenir que FileMaker gère fort bien les dates et dispose de nombreuses fonctions dédiées qui vous pemrettront d’extraire le mois ou l’année mais, très pratique, de retrouver le jour de la semaine.
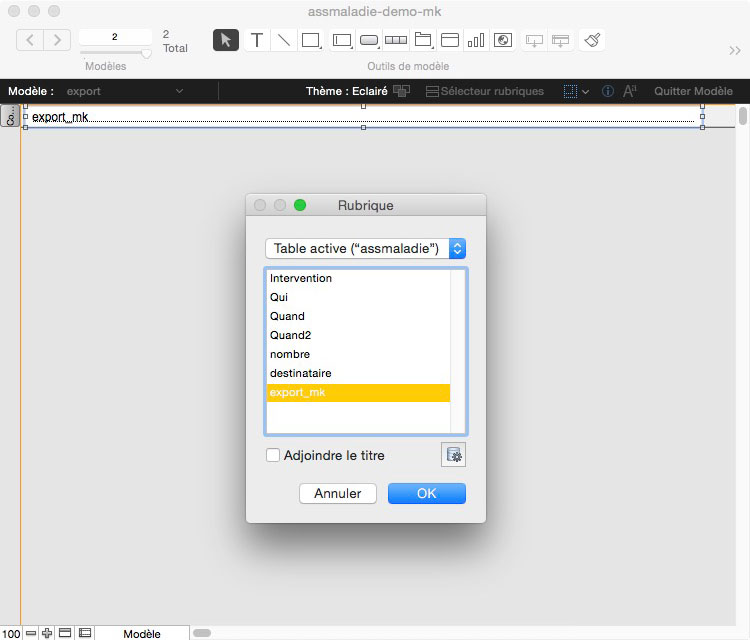
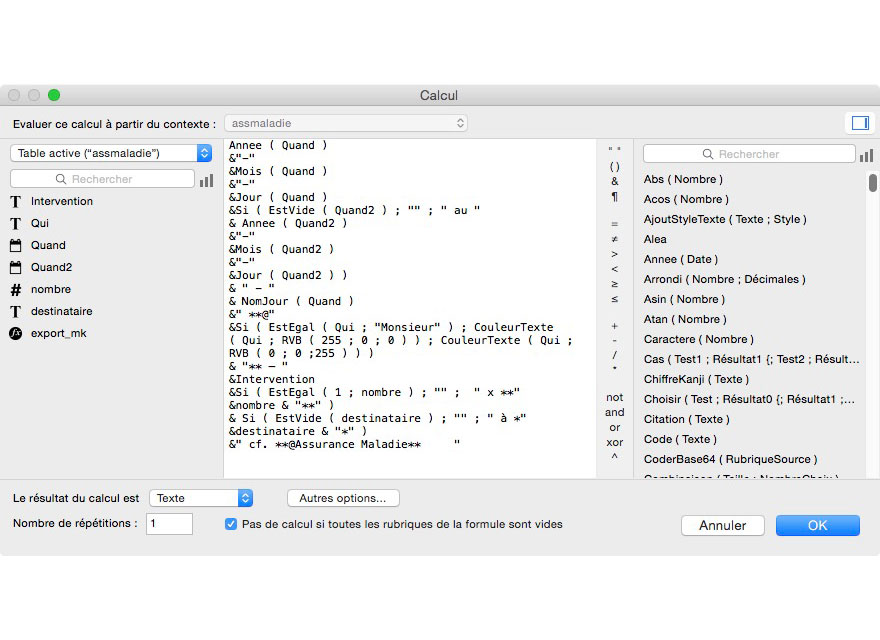
Enfin, en aval, il suffira de créer une rubrique calculée qui contiendra des conditions (de simples fonctions SI ou en testant l’existence de contenu dans une rubrique), amalgamera (la fameuse concaténation…) dans l’ordre souhaité de lecture les rubriques entrées.
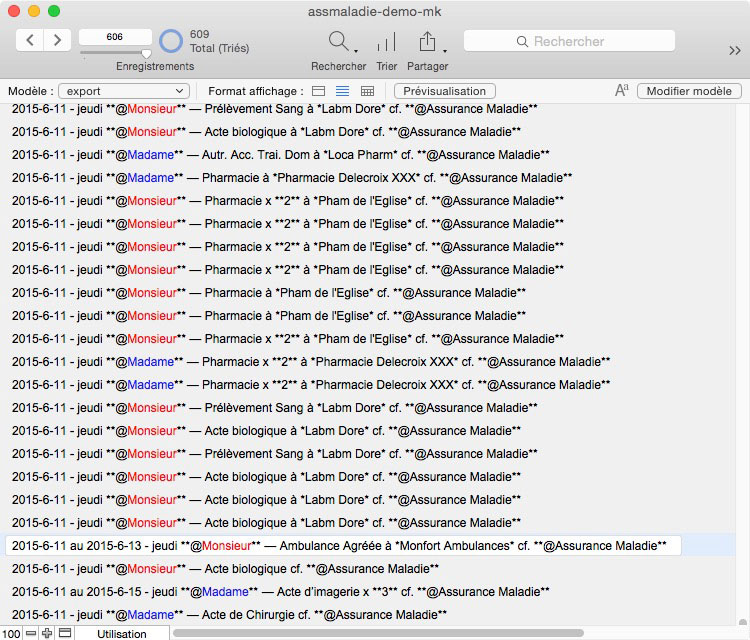
Il n’est pas compliqué dans cette rubrique calculée d’ajouter des balises pour signifier que telle info doit être en gras en la faisant précéder et suivre d’un simple **, le tout avec force & pour assurer les liaisons de cette concaténation.
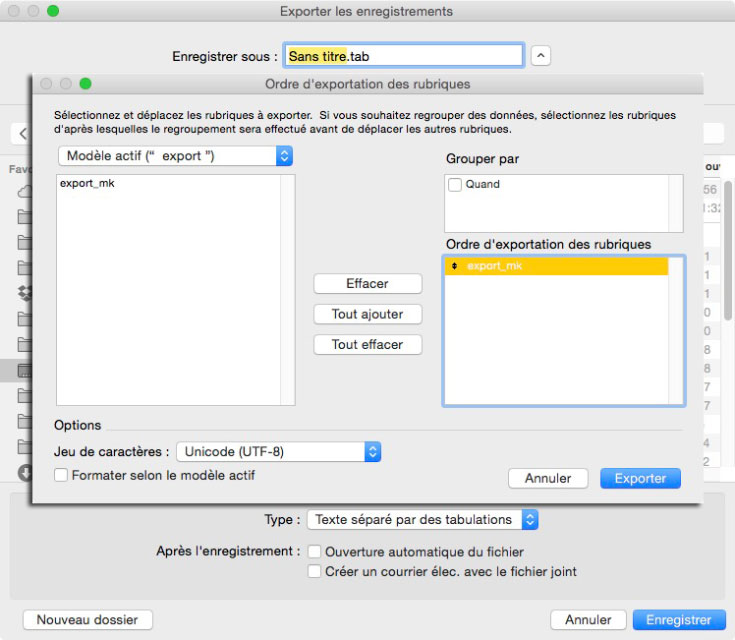
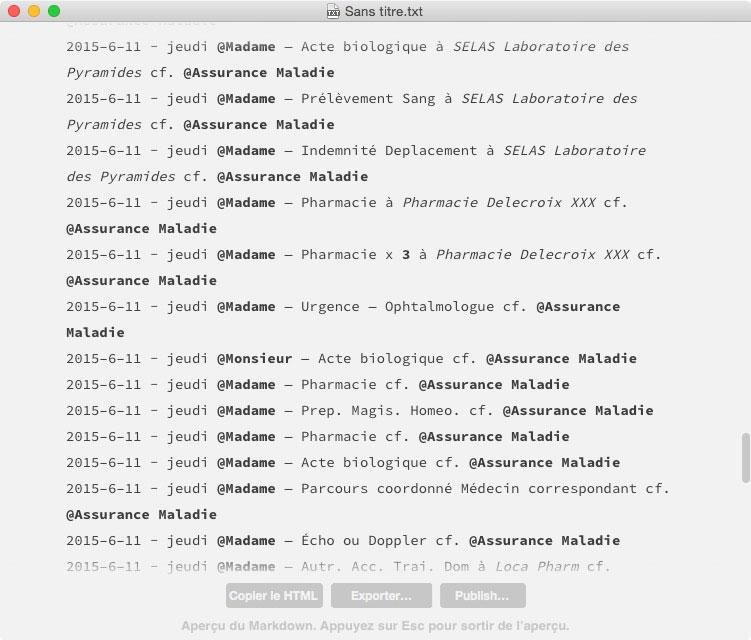
À vous ensuite de gérer l’export d’une sélection de données en triant sur date (descendant ou ascendant) avant de fabriquer le fichier de sortie (…du .tab qui n’est qu’un .txt). À l’arrivée, un fichier que n’importe quel traitement de texte pourra ouvrir mais avec un net avantage à ceux comprenant les balises Markdown. Ici dans Byword (11,99 €)…
Cette illustration basique est destinée à vous rappeller que si l’on peut gérer des solutions professionnelles haut de gamme avec FileMaker, ça fonctionne aussi très bien pour des besoins ultra basiques. Je ne vous fais pas un dessin, FileMaker est une fabuleuse moulinette à texte, Markdown compris.
À suivre…